Julia 1.0 came out well over 2 years ago. Since then a lot has changed and a lot hasn’t. Julia 1.0 was a commitment to no breaking changes, but that is not to say no new features have been added to the language.
Julia 1.6 is a huge release and it is coming out relatively soon. RC-1 was released recently. I suspect we have at least a few more weeks before the final release. The Julia Core team take a huge amount of care in not breaking any packages. So while that is all being checked and corner cases fixed, I think we have some time. Thus this post, reflecting not just on 1.6, but on everything that has happened since the 1.0 release.
Julia 1.6 will be the first “feature” release since 1.0. Prior to 1.0, all releases were feature releases; they came out when they were ready. Since then, all releases (except 1.6) have been timed releases. The release candidate is cut from the main branch every 3 months; and they are released after an extensive round of additional checking, which often takes weeks to months. Julia 1.6 was soft-slated to be the new long-term-support (LTS) version that would have bug-fixes backported to it for the next few years. The current LTS is Julia 1.0, which has now had 5 patch releases made. Since it was going to be supported for a long-time, people wanted to make sure everything good got in; thus it was a feature release. The core developers have demurred on if 1.6 will actually be selected to be the new LTS (even if it is selected, it won’t ascend to being the LTS til it stops being the current Stable).
My impression now is that they feel like it has too many cool new things; and that a few things didn’t quite make it in even with the extended release cycle. So it’s looking likely to me that 1.7 will actually be the LTS; but that it might also be a feature release – possibly this time a much shorter release period than usual. In practice I think for a lot of package maintainers 1.6 will be a LTS, in that that is the oldest version they will make sure to continue to support. There have been too many cool new things (as this post will detail) to stay back to only 1.0 features. Already a lot of packages have dropped support for Julia versions older than 1.3.
This post is kind of a follow-up to my Julia 1.0 release run-down. But it’s going to be even longer, as it is covering the last 5 releases since then and I am not skipping the major new features. I am writing this not to break down release by release, but to highlight features that, had you only used Julia 1.0, you wouldn’t have seen. Full details can be found in the NEWS.md, and HISTORY.md
Front-end changes
Soft-scope in the REPL
Julia 1.0 removed the notion of soft-scope from the language. I was very blasé about the change to for-loop bindings in my 1.0 release post. In fact, I didn’t even mention this particular change. It was #19324 for reference.
This was undone in in Julia 1.5 with #33864 for the REPL only. Now in the REPL, assigning to a global variable within a for-loop actually assigns that variable, rather than shadowing it with a new variable in that scope. The same behavior outside the REPL now gives a warning.
Personally, this change never affected me because I never write for-loops that assign variables at global scope. Indeed basically all code I write is inside functions. But I do see how this causes problems for some interactive workflows, e.g. when demonstrating something. See the main GitHub issue and the longest Discourse thread, though there were many others. It took over a year of discussion to work out the solution, particularly because many of the more obvious solutions would be breaking in significant ways.
Deprecations are muted by default
Julia 1.5+ doesn’t display deprecation warnings, unless you run julia with the --depwarn=yes flag.
This was me in this PR.
It’s not something I am super happy about, although I think it makes sense.
Using deprecated methods is actually fine, as long as your dependencies follow SemVer, and you use ^ (i.e. default) bounding in your Project.toml’s [compat], which everyone does, because it’s enforced by the auto-merge script in the General registry.
Often it is even necessary if you want to keep compatibility for a while.
Solving deprecations is a thing you should actively choose to do rather than casually when trying to do something else. In particular, when updating to support a new major release of one of your dependencies, you should follow a process. Something like:
- Check the release notes.
- Relax compat bounds
- Run your integration tests, if everything passes you are done.
- If tests failed, revert the change to compat bounds, then rerun your integration tests paying attention to deprecation warnings.
Updating your dependencies should be an active choice. Potentially one that is automated, but not one that you do while adding another feature (if you can help it).
The core of the reason we disabled them is because they were actually breaking things. Irrelevant deprecation warning spam from dependencies of dependencies was causing JuMP and LightGraphs to become too slow to be used. Further, since they were from dependencies of dependencies, the maintainers of JuMP and LightGraphs (let alone the end users) couldn’t even fix them.
Deprecation warnings are still turned on by default in tests, which makes sense since the tests (unlike normal use) are being run by maintainers of the package itself, not its users. This however still doesn’t make a huge amount of sense to me, since spam from deprecation warnings floods out the actual errors that you want to see during testing. For this reason, Invenia (my employer) has disabled deprecation warnings in the CI tests for all our closed source packages, and added a new test job that just does deprecation checking (set to error on deprecation and with the job allowed to fail, just so we are informed).
Hopefully one day we can improve the tooling around deprecation warnings. An ideal behavior would be to only show deprecation warnings if directly caused by a function call made from within the package module of your current active environment. I kind of know what we need to do to the logger to make that possible, but it is not yet something I have had time to do.
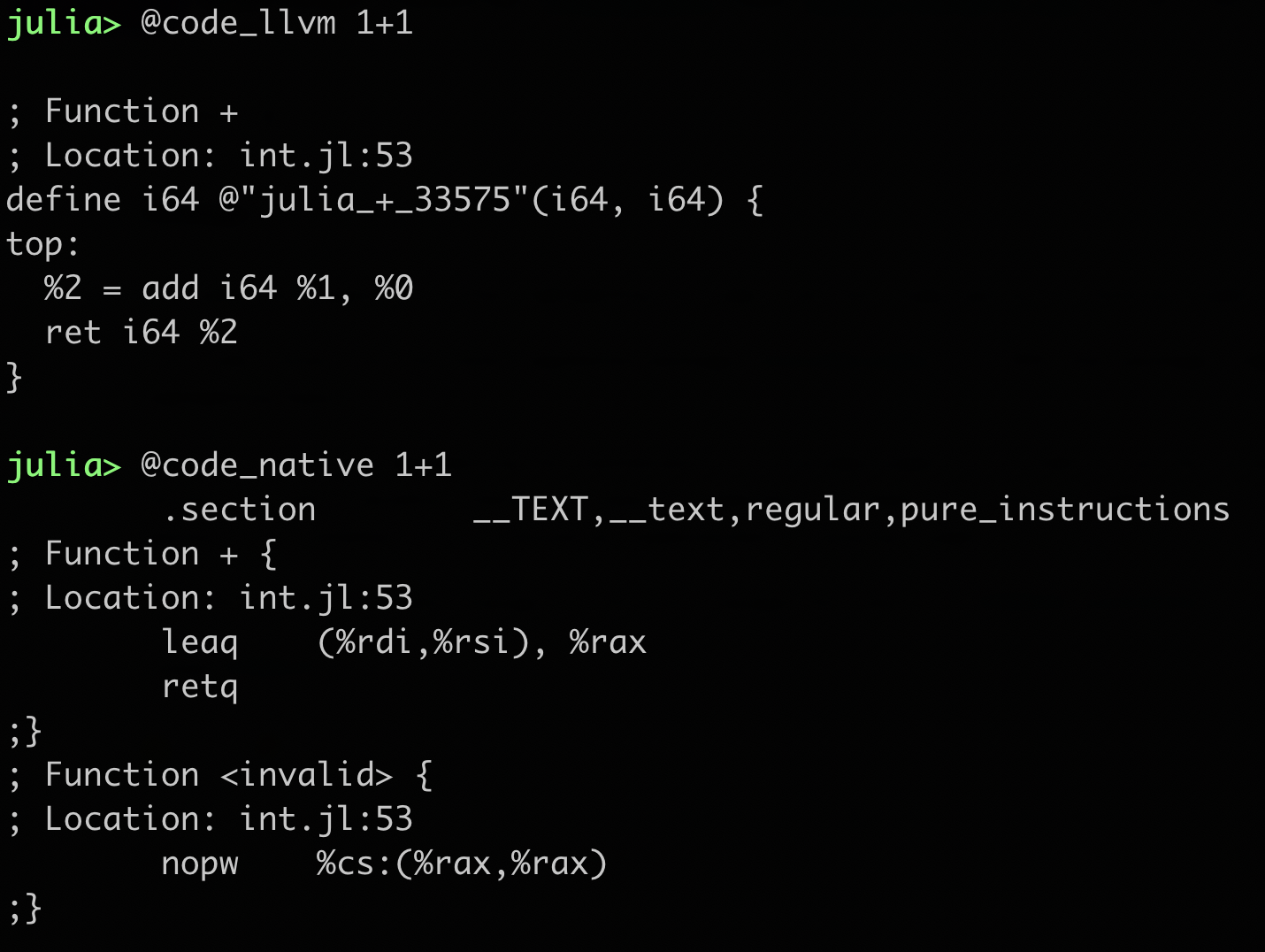
Code highlighting for code_llvm and code_native
This was added in #36634. This functionality was first implemented in ColoredLLCodes.jl, where it worked by monkey-patching the InteractiveUtils stdlib. That package does still work on Julia 1.0.
Julia 1.0:
Julia 1.6:
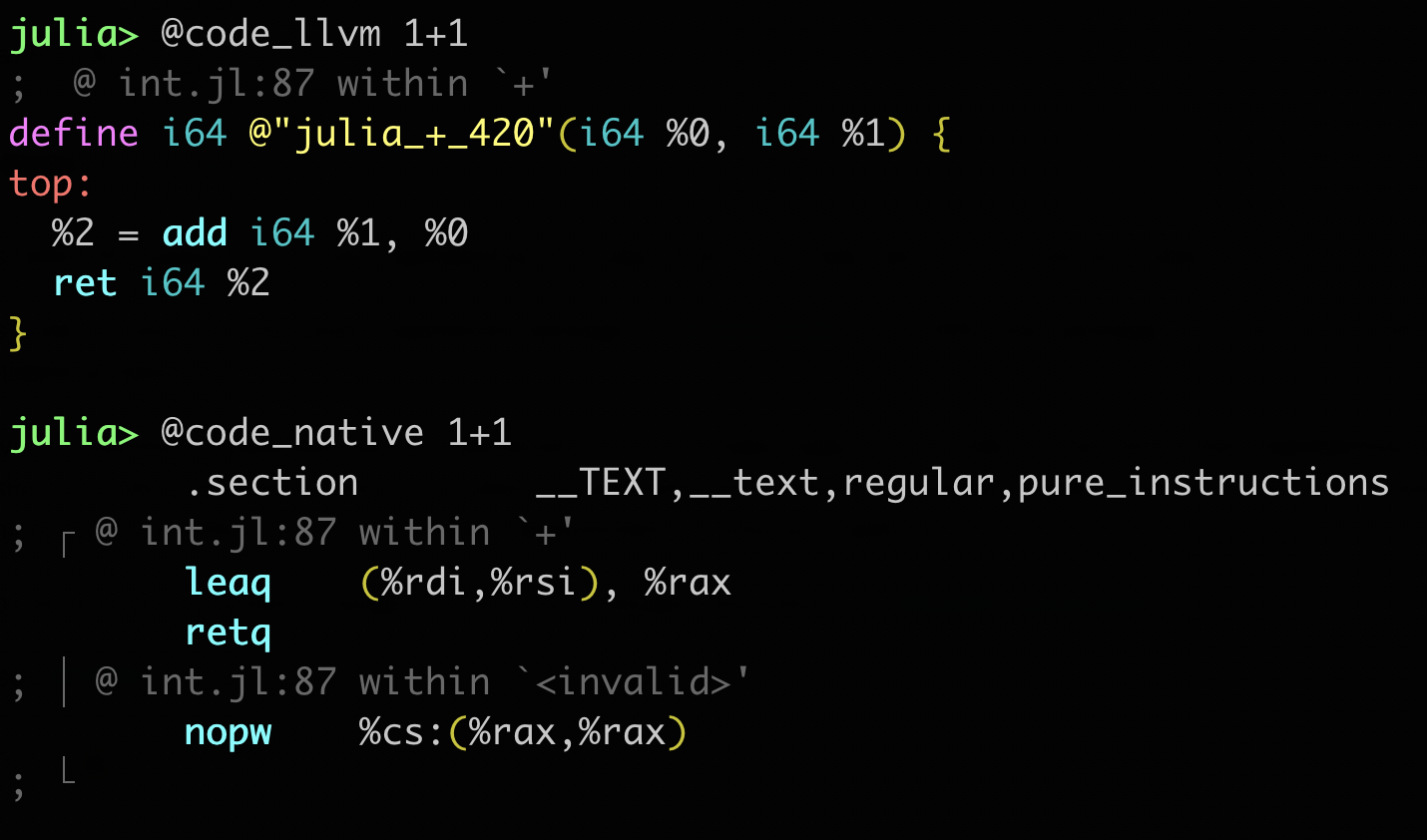
The REPL itself still doesn’t have syntax highlighting for Julia code though. The OhMyRepl package does provide that, and works for all versions of Julia. It is a lot more than a series of regexes though, so I don’t think we are going to see it built into Julia too soon. Probably one day, though, as its big dependencies are also required if the parser wants to move to be written in Julia (though I also don’t expect that any time soon).
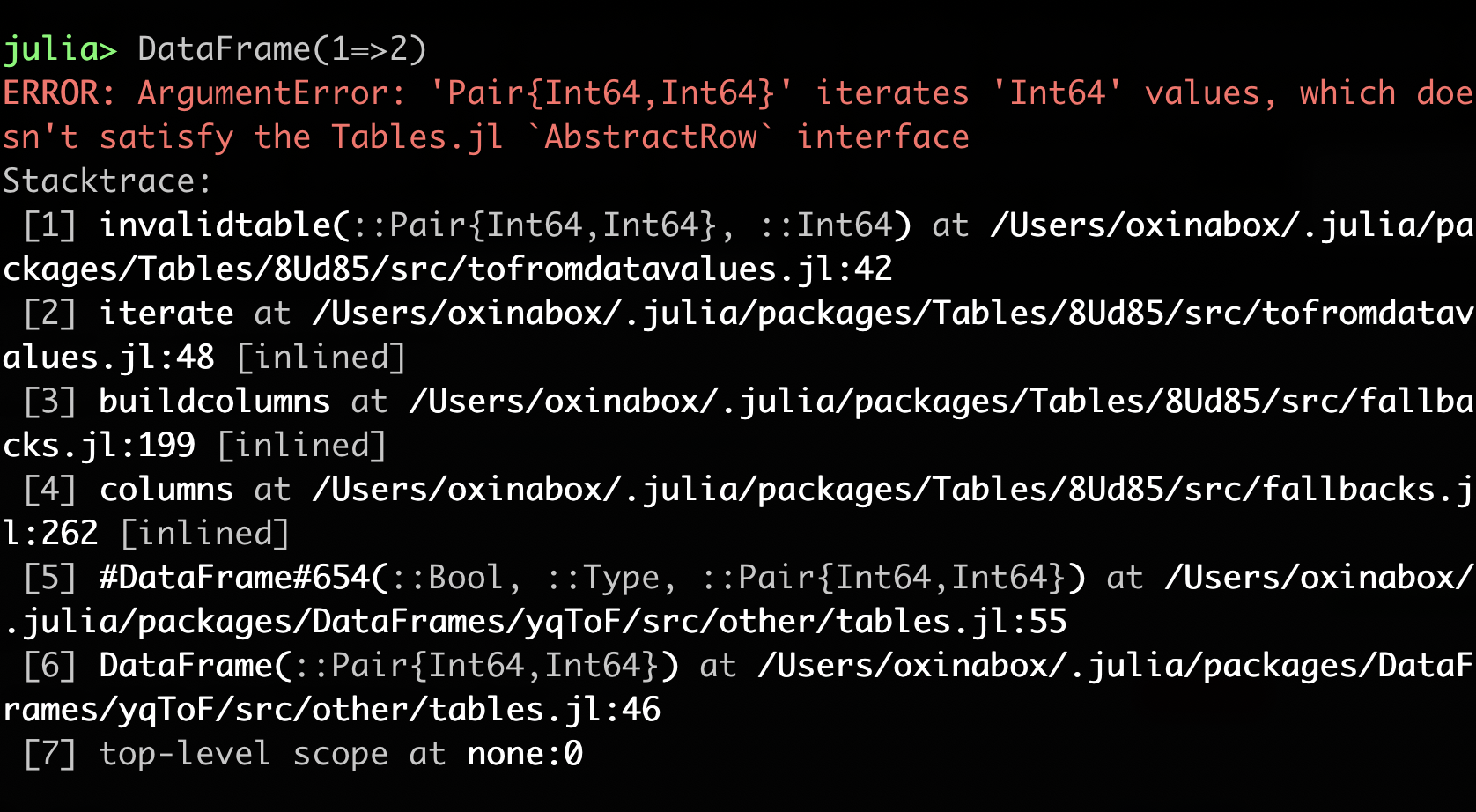
Clearer Stacktraces
Just like colored code_llvm, colored stack-traces also originated in a package that was doing some nasty monkey-patching: ClearStacktrace.jl.
This was added into Base itself in #36134.
Julia 1.0:
Julia 1.6:
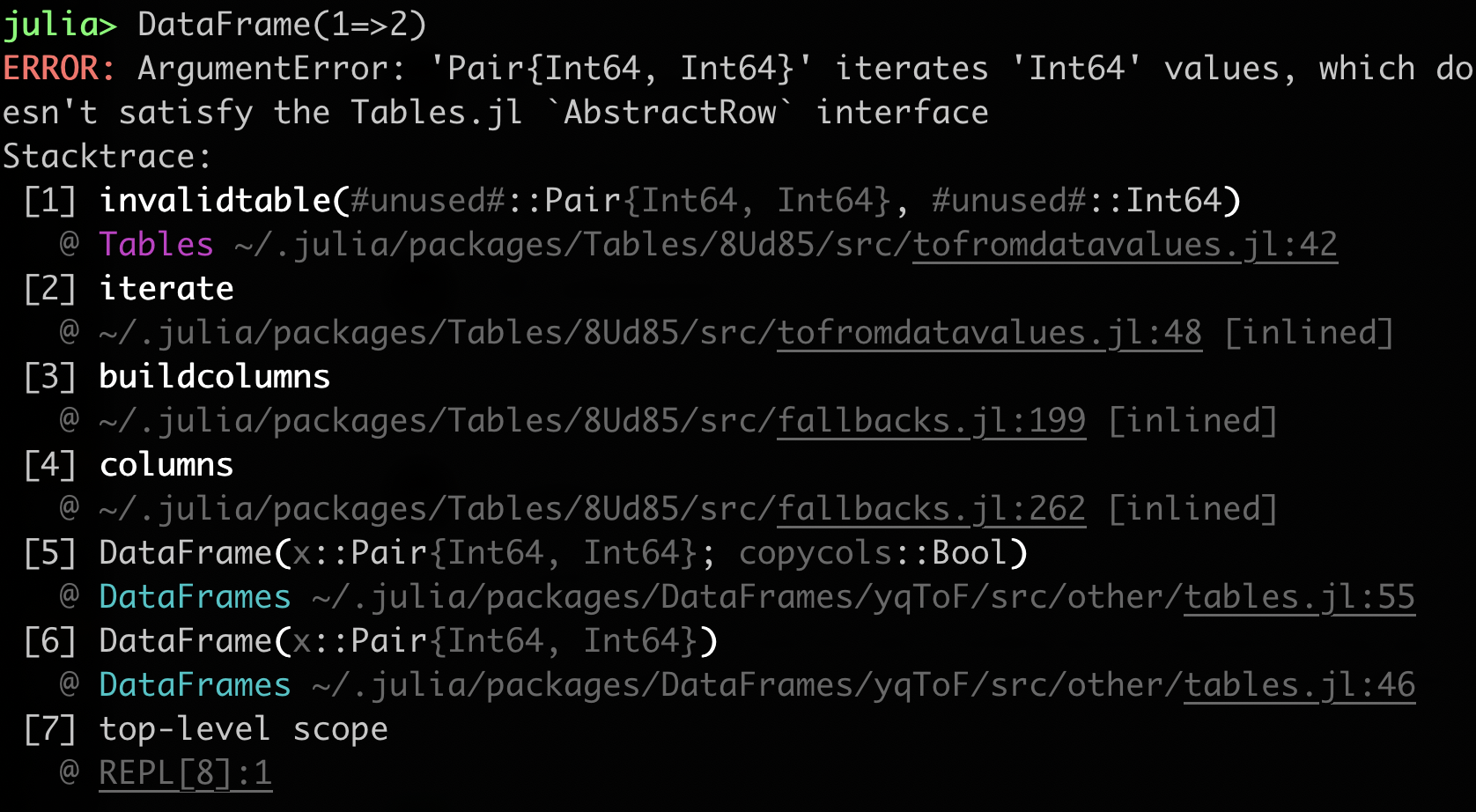
The first thing you probably notice is the colored package names, to make it more clear where the error is coming from.
You also should notice the dimming of type parameters to make complicated types easier to read.
Also the addition of argument names, and showing functions with keyword arguments as they are written, rather than as a weird #DataFrame#654 internal function.
The whole thing just looks more modern and polished.
Time Traveling Debugger
Julia 1.5 added built-in support for rr (Linux only for now).
This is not useful so much for debugging Julia code, but for debugging Julia itself.
If you get into one of the very rare situations where the language is doing something truly nonsensical, you can send a bug report recorded via rr and someone can debug exactly what is happening - even to the extent of diagnosing faulty RAM.
rr is an impressively cool piece of tech.
It records execution of a program, intercepting places (namely syscalls) that could be nondeterministic and storing the result.
It can then replay the recording (even on another machine), and see exactly what happened.
Allowing on to go into great detail on the state, and step backwards and forwards through time.
The rr integration is really nice and easy to use.
On a project I was running, I ended up getting a member of our architecture and operations team run it to submit a support request and they had no real troubles
(And they are by no means a Julia pro, they write mostly Cloudformation).
Syntax
import as
The syntax import A as B (plus import A: x as y, import A.x as y, and using A: x as y) can now be used to rename imported modules and identifiers (#1255).
This will be familiar to Python folks who love to write things like: import numpy as np.
I hope we never see it used that ubiquitously in julia.
I am quite happy with using Foo which imports into scope everything the author of Foo exported.
Python people find that super weird and scary; but it’s fine.
Note that in Julia, many (most?) things you use don’t belong to the scope of the module that defined them anyways; they are overloaded functions e.g. from Base.
So what you import doesn’t matter as much as you might think.
I recently learned that Haskell is like Julia with a default of importing all exports.
It has been fine for julia, and fine for Haskell for ages, though in neither is it required.
The real value of import FooBar as fb is not to have a short abbreviation so you can do fb.quux.
That was already possible via const fb = FooBar.
It is to handle cases where the package name itself conflicts with an identifier.
For example (as has often occurred) if one uses a Pipe in the REPL, and then later wants to load Pipe.jl via import Pipe then one gets a name clash before it can be even be loaded.
Now one can do import Pipe as PipingPipe.
NamedTuple/keyword arguments automatic naming
This feature felt weird when I first read about it, but it has quickly grown on me. How often do you write some code that does some processing and calls some other method passing on some of its keyword arguments? For example:
# Primary method all others redirect to this
foo(x::Bar; a=1, b=2, c=3) = ...
# Method for if x is given as components
foo(x1, x2; a=10, b=20, c=30, op=+) = foo(Bar(op(x1, x2)); a=a, b=b, c=c)
This new feature allows one to avoid writing (...; a=a, b=b, c=c), and instead write (...; a, b, c), where a, b, c are the name of local variables that align with the name of the keyword arguments.
# Method for if x is given as components
foo(x1, x2; a=10, b=20, c=30, op=+) = foo(Bar(op(x1, x2)); a, b, c)
This does come with the requirement to separate keyword arguments from positional arguments by ;, but I have always done this, and the two most popular style guides for Julia both require it (BlueStyle, YASGuide).
It feels like we are fully leveraging the distinction of keyword from positional arguments by allowing this.
Whereas the previous motivation for this distinction (vs e.g. C# and Python that allow any positional argument to be passed by name), was to make the name of positional arguments not part of the public API, thus avoiding changing it being a breaking change.
This new feature feels more … featureful.
The same syntax can be used to create NamedTuples.
julia> product = ["fries", "burger", "drink"];
julia> price = [2, 4, 1];
julia> (;product, price)
(product = ["fries", "burger", "drink"], price = [2, 4, 1])
This is particularly cool for constructing a NamedTuple of Vectors, which is a valid Tables.jl Table.
It is interesting to note that for the logging macros introduced in Julia 1.0, this is how they have always worked.
E.g. @info "message" foo bar and @info "message" foo=foo bar=bar display the same, which has always felt natural.
Lowering of '
In Julia 1.0 ' was lowered directly into a call to Base.adjoint.
This meant it was impossible to redefine what ' meant in your current module.
Now it lowers to a call to var"'", which is something you can overload.
In Base it is overloaded to Base.adjoint so nothing has changed.
People often think it is cool to overload this in automatic differentiation packages so that f'(x) gives you the derivative of f(x).
Furthermore, ' can now have Unicode suffixes added to it, to define a new suffix operator.
For example, the one in Base which makes A'ᵀ give transpose(A) (rather than the adjoint/hermitian transpose which is returned by A').
Pkg stdlib and the General Registry
Some of the biggest changes have been in maturing out Pkg3, and its surroundings.
Writing this section is a bit hard as there is no NEWS.md nor HISTORY.md for the Pkg stdlib, and the General registry is more policy than software.
Resolver willing to downgrade packages to install new ones (Tiered Resolution)
Until the tiered resolver was added, Julia would not change the version of any currently installed package in order to install a new one. For example, consider the following set of packages with different versions and compatibilities:
- Foo.jl
- v1
- v2
- Bar.jl
- v1 compatible with Foo v1
- v2 compatible with Foo v2
- Qux.jl
- v1: compatible only with Foo v1
If you did pkg"add Foo Bar Qux" you would end up with Foo v1, Bar v1, and Qux v1.
But if you first did: pkg"add Foo Bar" (which would install Foo v2, and Bar v2),
and then did pkg"add Qux",
then on Julia 1.0 you would get an error, as it would refuse to downgrade Foo and Bar to v1, as is required to allow Qux to be installed.
This meant that the package manager is effectively stateful, which turns out to be really counterintuitive.
The way to resolve this in practice was to delete the Manifest.toml, which is where the state is stored, and do it again as a single action.
This was a significant problem for test-time dependencies, where if you had a test-time dependency with an indirect dependency shared with a main dependency of the package, but that was only compatible with an older version of the indirect dependency, you would be unable to run tests as resolving the test-time dependency would fail.
With the new tiered resolver, pkg"add ..." will try a number of increasingly relaxed strategies to try and install the new package while making minimal changes to the versions of the existing packages that are already installed.
You can see the full description of the --preserve options in the Pkg docs.
- First it will try and avoid all changes.
- Then it will try and avoid changing the version of direct dependencies, but allow changes to the version of indirect dependencies.
- Then it will allow changes to direct dependencies, but will avoid changing the major (or minor pre-1.0) version, even if
Project.toml’s[compat]says it is allowed to. - Then it will allow changes to everything (as long as permitted by
Project.toml’s[compat]section) - Finally it will give up and error if it still can’t find a compatible set of packages that let it add the new one.
For a package with a fully filled in [compat] section in the Project.toml, it is always fine to allow changes to everything – which is what this will do if it has to.
If one hasn’t setup the [compat] section then this can be nice to minimize changes.
(But also: please setup your [compat] bounds, for your own sake.)
The net result of this is far more intuitive behavior for pkg"add ...".
If there is a compatible set of package versions then they will be found, regardless of whether new packages are added all at once or one at a time.
Precompilation
Precompilation has been enhanced a lot.
That is not the compilation that runs the first time a function is used in a session, but rather the stuff that runs the first time a package is loaded in an environment.
Or that can be run manually via pkg"precompile", or in 1.6+ that is run automatically when you exit Pkg mode in the REPL.
For a start, the precompilation cache no longer goes stale every time you swap environments. This was a massive pain in Julia 1.0, especially if you worked on more than one thing at a time. This was fixed in 1.3 to have a separate cache for each environment. It’s easy to forget this one, but it is actually one of the biggest usability enhancements since 1.0.
More dramatic, is the parallelism of precompilation added in 1.6. Precompiling a package requires precompiling all its dependencies first (and so forth). This is now done in parallel, and (as mentioned) is automatically triggered when you complete Pkg operations, in contrast to happening serially the first time a package is loaded. No more waiting 5 minutes the first time you load a package with a lot of dependencies. Further, the spiffy animated output shows you what is precompiling at any given time, as well as a progress bar, which makes it feel (even) faster.
You can see in the video below how much faster this makes precompilation.
Improved conflict messages
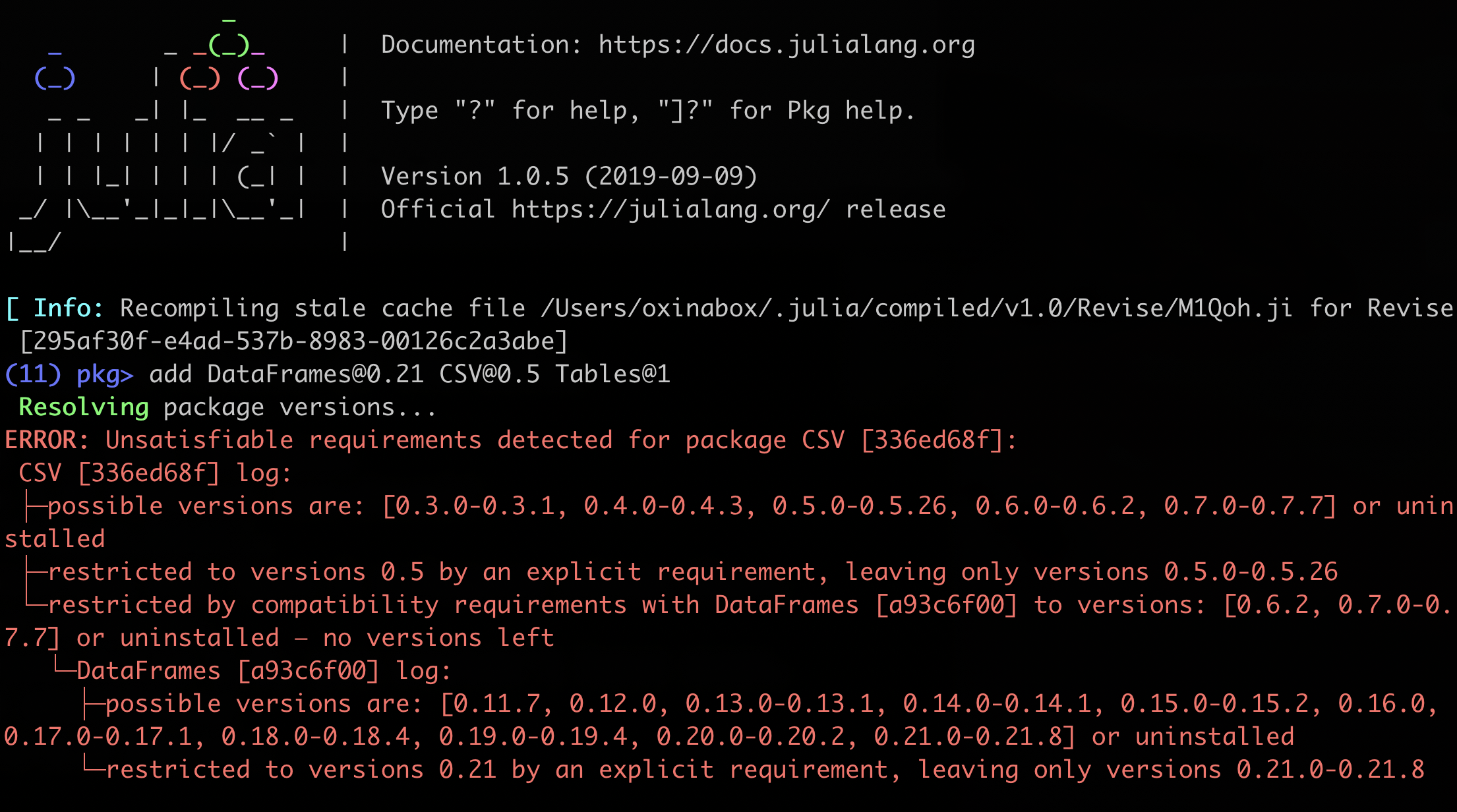
This is one of my own contributions. I am honestly really satisfied with it. Julia 1.0 conflict messages were a terrifying wall of text; the ones in 1.6 are (IMO) so much nicer.
Julia 1.0:
Julia 1.6:
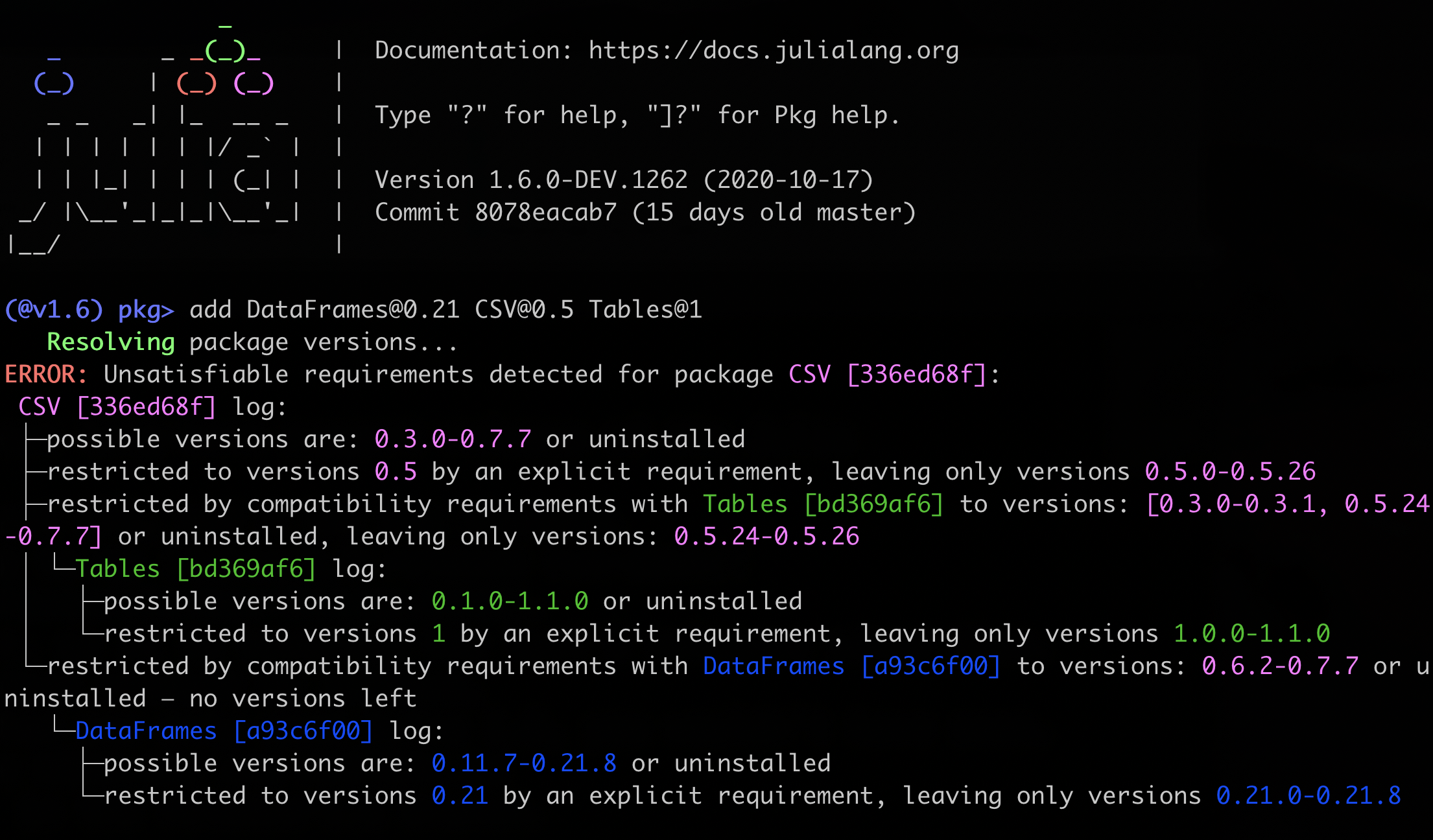
The two main changes are the use of colors, and compressing the version number ranges. No more giant red wall of numbers.
Colors were added to make it easier to see which version numbers are referring to which package. There is a bit of a problem in that it isn’t easy to make sure the colors don’t get reused, as there are not many in the 16 color list (especially when you skip a few like black, white and error red). Due to how Pkg constructs its error messages, basically every package in the dependency graph gets some message prepared for it, but not displayed, so just assigning them a color in turn gets it to loop around which still results in colors being reused. There is a way to fix that, but it is a big change to add structured log messages that are colored only once when they are displayed. We decided after much debate to assign colors based on the hash of the package name and shortened UUID. This means things have consistent colors for any packages still listed, even after you have resolves some conflicts. I think this is going to be a subtle improvement on ease of use.
As a cool hack, you can actually change the color list used. I originally wanted a much larger list of colors. To get that list you can run:
append!(Pkg.Resolve.CONFLICT_COLORS, [21:51; 55:119; 124:142; 160:184; 196:220])
The other change was consecutive lists of version numbers were compressed to continuous ranges. In 1.6, these ranges are split only if there is a version that actually exists between them that is not compatible. So normally we get just a single range, since compatibility is typically monotonic. In contrast, in 1.0, they were split if there was a potential version that could exist that is not compatible (even if that version doesn’t currently exist). This means they split every time the rightmost nonzero part of the version number was incremented. For something with a lot of pre-1.0 versions, that is a lot of numbers. I think the new method is much cleaner and easier to read.
Temporary Environments
Julia 1.5 added pkg"activate --temp" which will create and activate a temporary environment.
This environment is deleted when Julia exits.
This is incredibly handy for:
- Reproducing an issue.
- Answering questions on Stack Overflow etc.
- Cross-checking the behavior of the last release of a package you currently have
deved. - Quickly trying out an idea.
Remember that with Pkg, installing a version of a package you have installed before is incredibly fast.
Pkg doesn’t download it again, it basically just points to the existing version on disk.
So using pkg"activate --temp" to quickly try something out is indeed quick.
A more hacky use of it is after loading (via using) a package that you are working on, you can pkg"activate --temp" and install some of your test-time dependencies to reproduce a test failure without adding them to the main dependencies in the Project.toml.
Though there is a better way if you use test/Project.toml.
Test Dependencies in their own Project.toml
In Julia 1.0 and 1.1, test specific dependencies are listed in the [extras] section, and under [targets] test=[...]; with their compatibility listed in the main [compat].
It seemed like this might be extended for other things in the future, perhaps documentation.
But it was found that for documentation, a separate Project.toml worked well (as long as you pkg"dev .." the parent package directory into its Manifest.toml so it uses the right version of the package it is documenting).
The new test/Project.toml extends that idea.
One part of that extension is to remove the need to dev .., the other part is to make available all the main dependencies.
It actually works on a different mechanism than the docs.
It relies on stacked environments, which is a feature Julia has had since 1.0 via LOAD_PATH, but that is rarely used.
One advantage of this is that you can activate that Project.toml on top of your existing environment by adding the test directory to your LOAD_PATH.
I wrote some more details on exactly how to do that on Discourse.
It feels kind of hacky, because it is.
At some point there might be a nicer user interface for stacked environments like this.
BinaryBuilder, Artifacts, Yggdasil and JLL packages
This story was beginning to be told around Julia 1.0 time, but it wasn’t really complete nor built into Pkg until Julia 1.3. You can read the documentation on Artifacts, BinaryBuilder, and Yggdrasil for full details. This is the story about how Julia works with binary dependencies. As of now, it works really well.
Sometimes people misunderstand the claims about Julia solving the two language problem as saying everything should be rewritten in Julia.
Which is far from the truth, ain’t nobody got time for that.
Julia has always had great foreign function interfacing (FFI); like ccall (as well as PyCall, RCall, JavaCall, and a bunch of others, for non-C-style binaries).
While FFI makes it easy to call binaries, how about actually getting them onto your machine?
Before Julia 1.0, the standard was to run arbitrary code in the deps/build.jl file, which often used BinDeps.jl to download and compile things.
Around 1.0, this changed to having the deps/build.jl call BinaryProvider.jl to download a compiled binary built with BinaryBuilder.jl, and store that alongside the package code.
In Julia 1.3+, the Artifacts system basically brought the BinaryProvider part into the package manager.
Now the Pkg controls the downloads, stores them in a controlled location to avoid massive duplication, and allows for full compat control.
No more running arbitrary code during installs.
The integration of installing the binaries into Pkg for Julia 1.3 is a major reason why many packages have dropped Julia 1.0 support. While you can still use BinaryProvider.jl for the download, it is much cleaner and easier to just use Julia 1.3+ and have the Artifact system take care of it.
I feel it is worth mentioning BinaryBuilder here. While it has existed since before 1.0, it’s really grown. It’s a super smooth cross-compilation environment, that can be used to build binaries for every platform Julia runs on. This is an amazing tool, built on containerization. It’s the kind of build tool one dreamed of having 10 years ago. It’s far more general than Julia, and I know people have at least experimented with using it with Nim. I hope more things start using it.
A novel use of this infrastructure is ygg.
ygg is effectively an installer for Yggdrasil hosted binaries that runs outside of julia.
This pretty similar to a simple OS independent package manager (some-what like Conda or HomeBrew).
This is really neat, not simply because it is making use of all the work that went into cross-compiling the universe, but because it’s actually really useful.
ygg installs everything to the normal julia artifact storage location, and doesn’t require any kind of admin privileges.
This is huge for working on systems with restricted privileges, like university PCs.
I used to use junest for this, but it was a bit flaky because it used scary proot hacks.
When it broke, I often resorted to compiling things from source, so I could install them to my home directory.
I have had to bootstrap a lot of things following Linux From Scratch.
ygg leverages the fact that the BinaryBuilder cross-compilation setup has already sorted out how to make portable binaries.
Full Transition off METADATA.jl and REQUIRE files, and onto the General Registry
Even though Julia 1.0 had Pkg3 and was supposed to use registries, for a long time the old Pkg2 METADATA.jl pseudo-registry was used as the canonical source of truth. Registering new releases was made against that, and then a script synchronized the General registry to match it. This was to allow time for packages to change over to supporting Julia 1.0, while still also making releases that supported Julia 0.6. It wasn’t until about a year later that General registry became the one source of truth, and METADATA.jl was retired.
This was kind of sucky, because a lot of the power of Pkg3 was blocked until then.
In particular, since the registries compat was generated from the REQUIRE file, and the REQUIRE files had a kind of gross requirement specification, everyone basically just lower-bounded things, or didn’t bound compat at all.
Which made sense because with the single global environment that Pkg2 had, you basically needed the whole ecosystem to be compatible, so restricting was bad.
But Project.toml has the much better default ^-bounds to accept only non-breaking changes by SemVer.
And with per project environments, things don’t all have to be compatible – just things used in a particular project (rather than every project you might ever do).
Automatic Merging
Initially after the transition, all registry PRs to make a new release needed manual review by one of the very small number of General registry maintainers.
I am a big fan of releasing after every non-breaking PR. Why would you not want those bug-fixes and new features released? It is especially rude to contributors who will make a fix or a feature, but then you don’t let them use it because you didn’t tag a release. Plus it makes tracking down bugs easier: if it occurs on a precise version, you know the PR that caused it. But with manual merging it feels bad to tag 5 releases in a day. Now we have automatic merging, so it is fine. At time of writing, ChainRules.jl was up to 78 releases.
The big advantage of automatic merging is that it comes with automatic enforcement of standards.
In order to be auto-mergeable, some good standards have to be followed.
One of which is that that no unbounded compat specifiers (e.g. >=1.0) are permitted; and that everything must have a compat specifier (since unspecified is same as >=0.0.0)
That one is particularly great, since if one adds specifiers later that can’t be met, then it can trigger downgrades back to incredibly old versions that didn’t specify compat and that almost certainly are not actually compatible (despite saying they are).
To deal with that particular case, retro-capping was done to retroactively add bounds to all things that didn’t have them.
This was painful when it was done, since it rewrote compat in the registry, which made it disagree with the Project.toml in package repositories, which is always confusing.
But now that it is done, it is good.
Requirement to have a Project.toml
Finally, the legacy ability to pkg"dev ..." packages that had only a REQUIRE file and no Project.toml was removed in Julia 1.4.
You can still pkg"add ..." them if they were registered during the transition period.
But to edit the projects, they must have a Project.toml file, which is fine since all the tools to register releases also require you to have Project.toml now.
PkgServer
One of the big advancements between Julia 0.6 and 1.0 was switching Pkg to special-case pkg"add ..." for repos hosted on GitHub and fetch tarballs (available via GitHub’s API), rather than clone the repo with full history.
At JuliaCon 2018 everyone was raving about how much faster it was.
Except me and the 2 other Australians present.
We were like “Still slow, what are you talking about?”.
Turns out that GitHub’s connection to Australia (at least for that API), is slow.
Australian Internet has infamously high latency, downloading dozens of packages is often slow.
GitHub wasn’t optimized for this kind of use, it’s not a content distribution network.
Its optimized for occasionally cloning things you want to develop, not rapidly downloading dozens of things that you want to use.
The new PkgServer solves this. It is optimized for distributing packages. This was introduced as opt-in in Julia 1.4, and made the default in 1.5. For full details see the original issue that introduced the Pkg protocol, it has a ton of info at the top explaining how it all works. There are distributed PkgServers around the world.
Not only does this solve the latency problems of connecting to some GitHub server that is on the other side of the world, it also improves support for non-GitHub hosting. Its always been possible to host Julia packages on anything supporting git. There are over a dozen packages in General Registry hosted on GitLab for example. My employer, Invenia, has all our internal packages hosted on GitLab, and registered on our internal registry. But in effect, prior to PkgServer, GitHub was 1st class in Pkg, due to its download-as-a-tarball feature. It makes sense - GitLab and BitBucket don’t even provide an API for downloading a repo via content (tree) hash (only commit hash), so it can’t be implemented inside Pkg itself. But by going via PkgServer, everything can be consistently served.
PkgServer has not been without struggles, both social and technical. Early versions of the system stored some metrics, so that package authors could be informed of how many users their package had, what operating systems they used etc. After much debate, it was concluded that this might be too invasive, and it was removed before the Julia 1.5 release. On the technical side, it initially had some struggles with keeping up with the load, with some servers becoming overloaded. More recently its had some issues (hopefully now fixed) where it has not been able to see the latest releases of packages because it is still seeing an out-of-date copy of the registry.
As Jeff Atwood said:
There are two hard things in computer science: cache invalidation, naming things, and off-by-one errors.
 (XKCD 1845
(XKCD 1845Time To First Plot
People often complain about the “Time To First Plot” (TTFP) in Julia. I personally have never minded it – by the time I am plotting something, I have done minutes of thinking so 20 seconds of compilation is nothing. Plotting, it turns out, is basically a really hard thing for a compiler. It is many, many, small methods, most of which are only called once. And unlike most Julia code, it doesn’t actually benefit all that much from Julia’s JIT. Julia’s JIT is normally specializing code, and running a ton of optimizations. But plotting itself isn’t in the hot-loop – optimizing the code takes longer than running it the few dozen times it might be used unoptimized. To make a long-story short, plotting is the poster child example for Julia needing to compile things before it can run them.
Julia 1.0:
julia> @time (using Plots; display(plot(1:0.1:10, sin.(1:0.1:10))))
16.780888 seconds (29.55 M allocations: 1.609 GiB, 3.79% gc time)
Julia 1.6:
julia> @time (using Plots; display(plot(1:0.1:10, sin.(1:0.1:10))))
9.694037 seconds (18.29 M allocations: 1.164 GiB, 4.17% gc time, 0.40% compilation time)
Sure it is still not instantaneous, but it’s a lot faster than it was.
Note also that in the above timing I had already run precompilation, which seems fairest. Though as discussed earlier, precompilation caches often would be deleted in 1.0; and conversely are created much faster in 1.6 due to parallelization. If you were to count the precompilation time I regularly saw in 1.0, TTFP could be several minutes.
Invalidations
Consider a function foo with a method foo(::Number).
If some other function calls it, for example bar(x::Int) = 2*foo(x), the JIT will compile instruction for exactly the method instance to call – a fast static dispatch, possibly even inlined.
If the user then defines a new, more specific method foo(::Int), the compiled code for Bar needs to be invalidated so it will call the new one.
It needs to be recompiled – which means anything that statically dispatches to it needs to be recompiled, and so forth.
This is an invalidation.
It’s an important feature of the language.
It is key to extensibility.
It doesn’t normally cause too many problems, since generally, basically everything is defined before anything is called, and thus before anything is compiled.
A notable exception to this is Base and the other standard libraries. These are compiled into the so-called system image. Furthermore, methods in these standard libraries are some of the most overloaded, thus most likely to be invalidated.
A bunch of work has gone into dealing with invalidations better. Not just point-fixes to remove calls that were likely to be invalidated, but several changes to the compiler. One particular change was not triggering cascading invalidations for methods that couldn’t actually be called due the being ambiguous. As a result, a lot of user code that triggered invalidations on 1.5 no longer does so on 1.6. The end result of this is faster compilation after loading packages, since it doesn’t have to recompile a ton of invalidated method instances - i.e. a decreased time to first plot.
This has had a huge effect on Revise.jl which started to take several seconds to load when it gained the dependency on JuliaInterpreter.jl; which isn’t much, but when you do it every time you start Julia it is an annoying lack of snappiness. But thanks to this work, JuliaInterpreter, and thus Revise, now load in a flash.
A full discussion on the invalidations work can be found in this blog post.
Per-Module Optimization Flags
The compiler optimization level can now be set per-module using the experimental macro Base.Experimental.@optlevel n. For code that is not performance-critical, setting this to 0 or 1 can provide significant latency improvements (#34896).
Compilation and type inference can now be enabled or disabled at the module level using the experimental macro Base.Experimental.@compiler_options (#37041).
Recall that I said most of Julia compilation isn’t even that useful for plotting, since making it run fast isn’t a priority (but loading fast is).
@optlevel only controls which LLVM optimization passes run; which is right at the end of the compilation pipeline.
Turning off compilation and type inference on the other hand turns off a ton more.
These flags mean that plotting libraries and other similar things that don’t benefit from the optimizer can just not use the optimizer.
Internals
References to the Heap from the Stack (Performance)
This was promised in 2016 as a feature for 1.0 (released 2018), but we actually didn’t get it until 1.5 (released 2020) with #33886.
In short, the process of allocating memory from the heap is fairly slow*, whereas allocating memory on the stack is basically a no-op.
Indeed, Julia benchmarking tools don’t count allocations on the stack as allocations at all.
One can find extensive write ups of heap vs. stack allocations and how it works in general (though some mix the C specific factors with the CPU details).
In Julia, all** mutable objects live on the heap.
Until recently, immutable objects that contained references to heap allocated objects also had to live on the heap, i.e. only immutable objects with immutable fields (with immutable fields with…) could live on the stack.
But with this change, all immutable objects can live on the stack, even if some of their fields live on the heap.
An important consequence of this is that wrapper types, such as the SubArray returned from @view x[1:2], now have no overhead to create.
I find that in practice this often adds up to a 10-30% speed-up in real world code.
(* It’s actually pretty fast, but it is the kind of thing that rapidly adds up; and it is slow vs operations that can happen without dynamic allocations.)
(** Technically not all mutable objects live on the heap, because some never live at all, as they are optimized away entirely, and under certain circumstances they can actually be allocated on the stack. But as a rule mutable objects live on the heap.)
Manually Created Back-edges for Lowered Code Generated Functions
This is a very niche and not really at all user-facing feature. But it is important for some really cool things, like Cassette. To understand why this matters, it’s worth understanding how Cassette works. I wrote a blog post on this a few years ago. As well as the prior discussion on invalidations.
Julia 1.3 allowed back-edges to be manually attached to the CodeInfo for @generated functions that return lowered code.
Back-edges are the connections from methods back to each method instance that calls them.
This is what allows invalidations to work, as when a method is redefined, it needs to know what things to recompile.
This change allowed those back-edges to be manually specified for @generated functions that were working at the lowered code level.
This is useful since this technique is primarily used for generating code based on the (lowered) code of existing methods.
For example, in Zygote, generating the gradient code from the code of the primal method.
So you want to be able to trigger the regeneration of this code when that original method changes.
Basically, this allows code that uses Cassette.jl, IRTools.jl and similar approaches to not suffer from #265-like problems.
A particular case of this is for Zygote, where redefining a function called by the code that was being differentiated did not result in an updated gradient (unless Zygote.refresh()) was run.
This was annoying for working in the REPL, where you might e.g. change your neural nets loss function without redefining the network.
In that case, if you forgot to run Zyote.refresh() it would just train wrong.
Other things that this allows are two very weird packages that Nathan Daly and I came up with at the JuliaCon 2018 hackathon: StagedFunctions.jl and Tricks.jl.
StagedFunctions.jl relaxes the restrictions on normal @generated functions so that they are also safe from #265-like problems.
Tricks.jl uses this feature to make hasmethod, etc. resolve at compile-time, and then get updated if and when new methods are defined.
This can allow for defining traits like “anything that defines a iterate method”.
Base and Standard Libraries
Threading
Julia has full support for threading now.
Not just the limited @threads for loops, but full Go-style threads.
They are tightly integrated with the existing Async/Task/Coroutine system.
In effect, threading works by unsetting the sticky flag on a Task, so that it is allowed to run on any thread.
This is normally done via the Threads.@spawn macro, which replaces the @async macro.
Interestingly, the @threads for macro still remains, and doesn’t actually use much of the new machinery. It still uses the old way which is a bit tighter if the loop durations are almost identical.
But the new threading stuff is fast, on the order of microseconds to send work off to another thread.
Even for uses of @threads for, we get some wins from the improvements.
IO is now thread-safe; ReentrantLock was added and is the kind of standard lock that you expect to exist.
It has notifications on waiting work, etc.; and a big one: @threads for can now be nested without things silently being wrong.
A lot of this actually landed in Julia 1.2, but Julia 1.3 was the release we think of as being for threading, as it gave us Threads.@spawn.
Also, in Julia 1.6, we now have julia -t auto to start Julia with 1 thread per (logical) core.
No more having to remember to set the JULIA_NUM_THREADS environment variable before starting it.
5-arg mul!: in-place generalized multiplication and addition
The 5 arg mul!(C, A, B, α, β) performs the operation equivalent to: C .= A*B*α + C*β, where α, β are scalars and A, B and C are compatible mixes of scalars, matrices and vectors.
I am still of the opinion that it should have been called muladd!.
This is the human-friendly version of BLAS.gemm! (i.e. GEneralized Matrix Multiplication) and its ilk, thus the name mul!.
It promises to always compute the in-place mul-add in the most efficient, correct way for any AbstractArray subtype.
In contrast, BLAS.gemm! computes the same thing, but with a bunch of conditions.
It must be a strided array containing only BLAS scalars, and if one of the inputs is conjugated/transposed you need to input it in non-conjugated/transposed form, and then tell BLAS.gemm! via passing in C or T rather than N.
5-arg mul! takes care of all that for you dispatching to BLAS.gemm! or other suitable methods once it has that all sorted.
Further, the existing 3-arg mul!(C, A, B) is a special case of it:
mul!(C, A, B) = mul!(C, A, B, true, false) (true and false being 1, and strong 0).
So you can just implement the 5-arg form and be done with it.
I personally didn’t care about 5-arg mul! at all for a long time.
It was yet another in-place function in LinearAlgebra that I would never use often enough to remember what it did, and thus wouldn’t use.
But I realized that it is a crucial function for my own area: automatic differentiation.
mul!(C, A, B, true, true) is the in-place accumulation rule for the reverse mode equivalent of the product rule.
You can now print and interpolate nothing into strings.
This is one of mine #32148, and I find it is such a usability enhancement.
So many small frustrations in Julia 1.0 related to interpolating a variable containing nothing into a string, often occurring when you are adding a quick println to debug something not being the value you expected, or when building a string for some other error message.
Arguably both of those are better done via other means (@show, and values stored in fields in the error type); but we don’t always do what is best.
Sometimes it is expedient to just interpolate things into strings without worrying about what type they are.
Base.download now using libcurl
For a very long time, the download function which retrieves things over HTTP was implemented with an amazing hack:
It conditionally shelled out to different programs.
On Windows it ran a mildly scary PowerShell script.
On Unixen it first tried to use curl, then if that wasn’t installed it tried to use wget, and then if that wasn’t installed it tried to use fetch.
It’s low-key amazing that this worked as well as it did – very few complaints.
But as of 1.6, it now uses libcurl.
Using libcurl everywhere gives consistency with proxy settings, and protocol support (beyond HTTP) across all platforms.
It also has a more extensive API via the new Downloads.jl standard library. It can do things like progress logging, and it can retrieve headers. I have tried getting headers via conditional different command-line download functions before, it’s a small cup of nightmare fuel; and I ended up swapping out to HTTP.jl for that. It wouldn’t be too surprising if eventually we see libcurl swapped out for code extracted from HTTP.jl for a pure Julia solution. HTTP.jl works wonderfully for this, but I suspect untangling the client from the server is just a bit annoying right now, particularly as it is still evolving its API.
Definable Error Hints
Experimental.register_error_hint
allows packages to define extra information to be shown along with a particular type of error.
A really cool use of it was proposed on Discourse:
you could add an error hint to MethodError that says to check that an interface has been implemented correctly.
This has the advantage of pointing the user in what is most likely the right direction.
But it doesn’t have the problem of really confounding them if you are wrong, since the original MethodError information is still shown (See my earlier blog post on the NotImplementedException antipattern).
Right now this is not used anywhere in the standard libraries.
At first, I thought that made sense since they can just edit the original show_error.
But now I think since it can be used for a subset of a particular type of exception it could well be useful for some of Base’s interfaces exactly as described above.
According to JuliaHub search, right now there is just one package using it:
ColorTypes.jl is using it to explain some consensual type-piracy, where for some functions on its types you need to load another package.
This is an experimental features, so it’s not covered by the SemVer guarantees of the rest of the language. Still it’s neat, and I don’t expect it to go away, though I also don’t expect it to graduate from experimental status until a bunch of people are using it. Which they will probably do as people start dropping support for older Julia versions.
A bunch of curried functions
Julia has ended up with a convention of providing curried methods of functions if that would be useful as the first argument for filter.
For example, filter(isequal(2), [1,2,3,2,1]) is the same is filter(x->isequal(x, 2), [1,2,3,2,1]).
In particular these are boolean comparison-like functions with two arguments, where the thing being compared against is the second.
Julia 1.0 had isequal, == and in.
Since then we have added:
isapprox, <,<=,>, >=, !=, startswith, endswith, and contains.
Aside: contains is argument-flipped occursin.
It was a thing in Julia 0.6, but was removed in 1.0 and now has been added back.
We added it back primarily so we could have the curried form, and to match startswith and endswith.
A ton of other new and improved standard library functions
I am not going to manage to list all of them here. But I will list some of my standout favorites.
@time now reports how much time was spent on compilation.
This is going to help prevent people new to the language from including compilation time in their benchmarks.
It is still better to use BenchmarkTools.jl’s @btime, since that does multiple samples.
But now that too can report time spent on compilation.
It’s also useful for identifying if certain functions are taking ages to compile.
Which I guess is its theoretical main point, but I think preventing people from benchmarking wrong is going to come up way more often.
The experimental Base.@locals
was added, which returns a dictionary of local variables.
That one surprised me; I though being able to access a dictionary of local variables would get in the way of the optimizer, since it would prevent it from being able to optimize variables that are used for intermediate values away entirely.
However, the way it functions is to generate code with creates and fills dictionary of with references to variables where it is used.
The dictionary is not maintained at all times.
So this shouldn’t block optimizations in functions that don’t use it.
But the compiler folks know better than I do.
splitpath is added, it’s the opposite of joinpath.
Kind of silly we didn’t have that, and had been bugging me at least since 0.6.
Similarly, I have wanted eachslice and its special cases: eachrow & eachcol since Julia 0.3 when I first started using the language.
These are super handy, for example when you want to iterate through vectors of the rows of a matrix.
redirect_stderr and redirect_stdout now work with devnull.
So one can run some code while suppressing output easily as follows:
julia> redirect_stdout(devnull) do
println("You won't see this")
end
This is just handy, doing it without this is seriously annoying.
readdir now accepts a join=true|false keyword argument so that it returns paths with the parent dir.
This is good, almost every time I use readdir I used it as:
joinpath.(x, readdir(x)).
It is slightly cleaner (and faster) to be able to do readdir(x; join=true).
I think for Julia 2.0 we should consider making it the default.
Also added was a sort argument, which I don’t see the point of so much, since sort(readdir(x)) seems cleaner than readdir(x; sort=true); and because I rarely rely on processing files in order.
ccall is now available as a macro @ccall which lets you specify the types in a similar way to Julia’s normal type-assertions.
There was a short juliacon talk about this
So now one can do @ccall(sqrt(4.0::Cdouble)::Cdouble)
rather than ccall(:sqrt, Cdouble, (Cdouble,), 4.0,)
This is what ccall always should have been.
In Julia 1.7, invoke is getting the same treatment..
In 1.5 NamedTuples got a similarly styled macro to help construct the types.
This was added in #34548.
Generally when working with NamedTuples you don’t need to mention the type but when you do it was quite verbose and ugly.
Now you write: @NamedTuple{str::String, x::Float64} rather than NamedTuple{(:str, :x), Tuple{String, Float64}}.
More “Why didn’t it always work that way” than I can count
Since 1.0’s release, there have been so many small improvements to functions that I didn’t even know happened, because I assumed they always worked that way.
Things like startswith supporting regex, parse working on UUIDs,
accumulate, cumsum, and cumprod supporting arbitrary iterators (#32656).
Julia 1.6 is one hell of a more polished language.
Thanks to all the people who contributed to editing the post.
Especially: Chris de Graaf, Nils Gudat, Miguel Raz Guzmán Macedo, Mosè Giordano, and Eric Hanson.